Tree Point Cloud Parameters Finder
The "Tree Point Cloud Parameters Finder" project is a C++ application that allows to determine the tree parameters: height, drip line diameter, trunk diameter from a laser scan point cloud. Here are examples of what it measures:
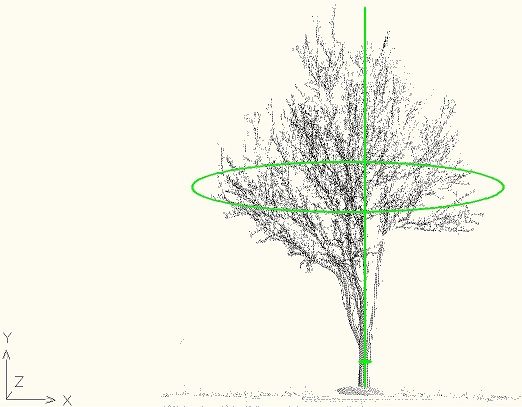
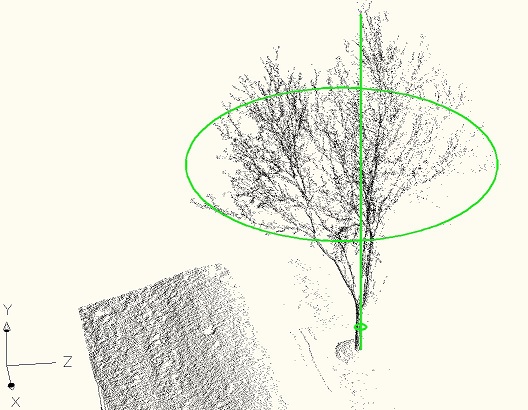
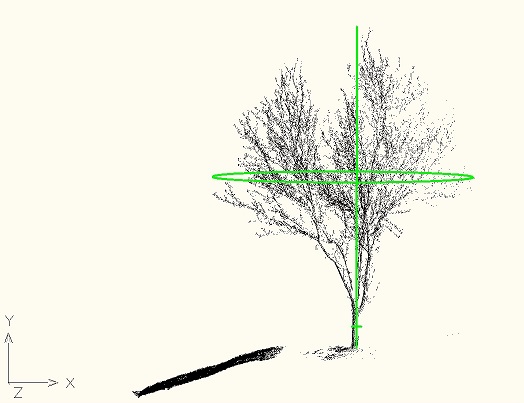
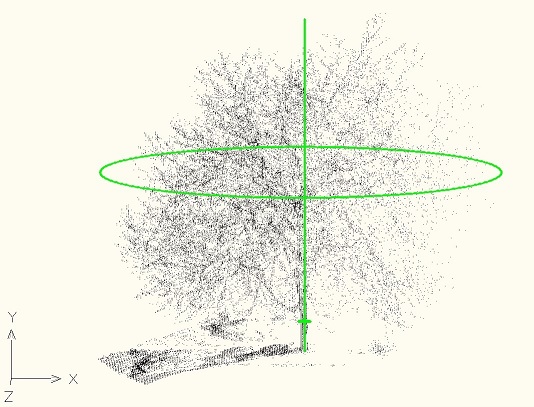
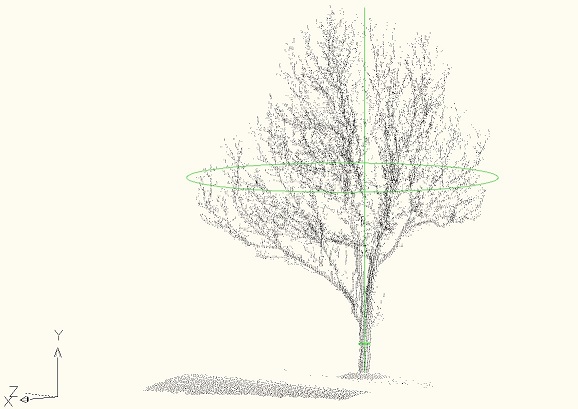
Compiling/Usage
Two types of binaries could be compiled from the source: SmTreePc.arx plug-in for AutoCad 2010...2013 (both win32 and x64 versions) and a Windows console application SmTreePc.exe (both win32 and x64 versions too). The console .exe versions are compiled from the Visual Studio project configurations named with 'Console' suffix. Note, the console .exe doesn't depend on the ObjectArx as well as on other libraries except for the standard C++ ones.
Arx usage: load SmTreePc.arx into AutoCad and type PC_ADD. Provide a point cloud txt file path as an argument for that command, e.g. "PC_ADD z:\pcs\scans\Tree1.txt". This command shows the cloud and prints the tree parameters. The debug configuration of this command draws a line and two circles correspondent to the measured parameters.
Console command usage: SmTreePc.exe file_name , e.g. "SmTreePc.exe z:\pcs\scans\Tree1.txt"
The input point cloud should be in txt point cloud format, in feet units, should contain a tree (or something like tree) scan, one shot scans are allowed.
-
Command output looks like the following:
Tree parameters are calculated: Height: 29.147949 Dripline diameter: 23.591715 Trunk diameter: 0.860223
Base idea behind the OO-decomposition for the point cloud data indexing.
A Container-Indexer-Index decomposition approach is used here as a way for the point cloud data storage and retrieval.
In wide sense, this approach could be described the next way:
The point cloud points are stored within a Container that has no additional information about them. A point cloud could be read into the Container from a file with some Reader.
After that, depending of a task to solve, particular Index could be built. Basically,
it's not specified from the beginning if the Index would contain 'back ref indexes' for the points or
some other data. The Index defines a data structure optimized in some specific sense that we want to apply to the raw data stored within the Container only. We can have as many indexes for a point cloud as we want, as well as we can delete unneeded indexes as soon as possible without the initial data container deletion.
The Indexer is an abstraction for a correspondence function between the Container and Index. The correspondence is for sure not restricted to be bijection only, it could be surjection too.
This approach allows to have most flexible (because we don't tie the system to some optimized container types like octree or kd-tree from the beginning - we just have a possibility to derive them when needed) and most memory efficient (because we can free memory as soon as particular Index is not needed) solution at the root. The time efficiency is not less than for the usual approaches, since we can easily derive all usual containers on this base without any additional seek/map function introduction.